On the 27th of November, Rob Meaney will spend an exciting hour on The Club tapping away on his keyboard answering any of your questions related to Operability. Designing Operability into your product can be a hugely powerful means of managing risk. Operability is a key ingredient in enabling teams to deliver value quickly, reliably and sustainably with without compromising quality. So what is Operability and how can we get started? Ask your question to get it answered.
I will answer your questions on Operability, for example, you could ask about:
Understanding what Operability is
Getting started in Operability and how to introduce it
The benefits of Operability
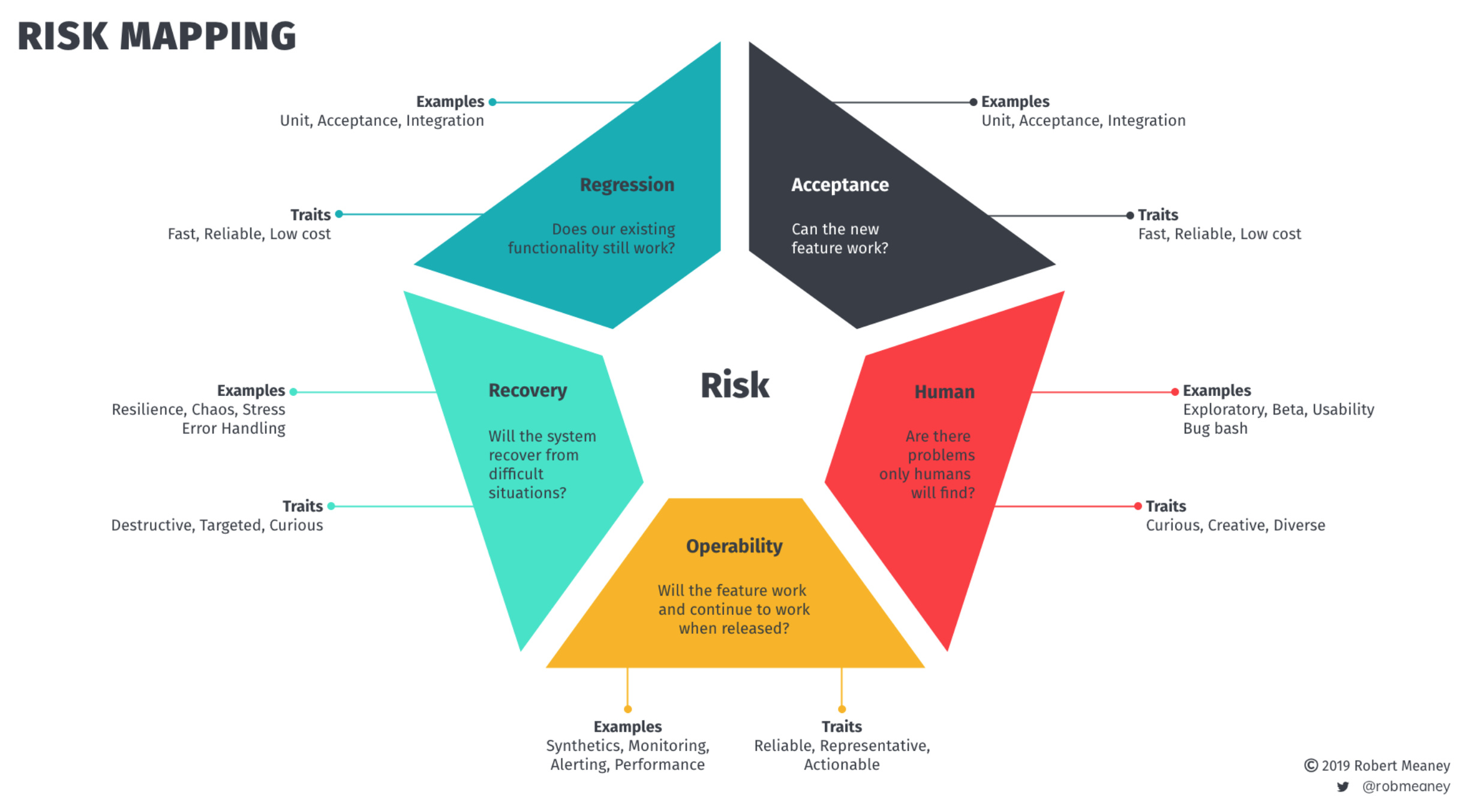
The core components of Operability
Operability examples
Get all your questions in by 27th November before 7pm GMT and I’ll do his best to answer them during my Power Hour!
What is Operability and why is it important? If someone were to say that Operability is not important, how would you try to persuade them to change their mind?
What are your tops tips when introducing Operability into a mature product which is already live to customers? How do you handle Manual vs Automated Regression testing and tools? How much coffee is it acceptable to drink in a single 4 hour period?
My idea of “operability” is all the “ops” side of DevOps, including logging, monitoring, observability, configuring pipelines… though for me there’s a lot of gray area there (which makes sense, if we’re talking about DevOps). How do you specifically define operability?
Software operability is a measure of well as software system works when operating in Production. A highly operable system is one that minimises the time and effort required to keep the system in a healthy state.
Software operability is a hugely important consideration as it allows us to deal with the reality of running software in Production. Operability not only allows us to easily deploy and test changes in Production but also detect, debug and fix issues when they occur.
I see a focus on Operability as a key component in managing risk effectively and is essential when dealing with complex distributed systems. A focus on Testability allows us to manage risks we can anticipate, minimising the likelihood of failure while a focus on Operability allows us to manage risks that we can’t anticipate minimising the impact of failure when it does occur.
The best way to persuade someone of the value of Operability is to expose them to the pain of a hard to Operate system. Invite this person to an incident learning review where everyone involved in a customer-impacting incident talks through the experience from detection all the way to resolution. Discussing the good and bad experiences and understanding the time and effort involved in getting to resolution is a very compelling argument. Even better again is to have the whole team take responsibility for Operating the system so that they personally feel the pain.
We consider Operability from the very start. We start any piece of work using a technique called user story mapping, as part of this process we invite Customer Support Engineers and Operations Engineers along. We talk through how we will operate and support this new functionality in Production and add the user stories to capture their needs.
As testers on the team, we try to highlight Risk early buy asking simple questions like:
How could we deploy this change to Production as quickly and safely as possible?
How could we identify problems as quickly and safely as possible in Production?
How could we minimise the impact of problems in Production?
How could we correct problems as quickly and safely as possible?
I would begin introducing Operability through the use of Deployment Learning Reviews and Incident Learning Reviews. So after doing a deployment get everyone involved in the process together in a safe space where they can openly and honestly share their experiences. Talk about the good to reinforce current good practice and talk about the bad to identify areas for improvement. Once everyone has had the opportunity to share their experience identify a single improvement that people agree would make a significant positive impact and work together to get this improvement in place.
Similarly, after each customer-impacting issue gather those involved in a safe, blame-free environment, talk about their experience and identify a single improvement that can improve the experience. By continually reviewing and acting on improvements to deploys and customer incidents the Operability of the system will improve.
There’s a well known saying in the DevOps world that goes “You Build it you run it”. I believe that the whole team has responsibility for Operability. Managers have a responsibility to give teams the time to invest in Operability, Developers have a responsibility to design and develop systems with Operability in mind, Testers have a responsibility to test that the systems are Operable and Operations have a responsibility to feedback any pain they feel when operating the system.
My horror story comes from a startup that I worked in 5 years ago now. The company was beginning to get traction with some of the biggest retailers in the world. Our software was embedded in their cart page so our platform had to be available all the time, responsive to with 500ms & scalable to fluctuating customer needs. Initially, I built out a suite of automated tests but this gave me no feedback on the attributes above. Also, I found that no matter how much automation and testing I did pre-prod we still had customer issues when we deployed new changes. The challenge was that we had no way to recreate the volume, variety or complexity of Production like traffic in our test environment. So we decided to focus on Operability so we could safely deploy and test in Production.
We applied the CODS operability model limiting our Risk exposure using Blue Green Deploys, added observability by instrumenting the code to visualise critical customer pain points, Decompsed our deploys into single change sets and simplidied the deployment so it was a single click of a button. The result was a huge acceleration in the rate at which we could deliver value to our customers without negative impact to our customers
For me Operability is about how easy your system is to Operate in Production.
How easy is it to understand your system?
How easy is it to deploy changes?
How easy is it to test changes in Production?
How easy is it to detect problems?
How easy is it to understand the impact of the problem?
How easy is it to minimise the impact of the problem?
How easy is it to debug problem?
How easy is it to fix and retest the problem?
How easy is it to repair the damage caused by the problem?
Learning from production use - for example, watching how people use a new capability or indeed whether anyone uses it at all - and using this to drive new development as well as focus future testing - is that part of operability? Or testability? Or neither? Or both?